
前言
文献还是要读的,怎么可能让Python帮你读文献?不读文献怎么搞科研???
但是真的有时候很懒很懒....下周就要和老板汇报工作了,然而还有一堆已经下好的文献还没读,PPT里也明显缺了一大块内容需要文献来填补....
于是我开始耍起小聪明了,之前女朋友说想学自然语言处理(NLP),然后也没有然后了。但是我当时花了几个小时看了下Python下NLP的实现,觉得可以用在文献的关键词提取上呀!虽说不能帮我读文献,但是至少能帮我快速区分这篇文献的大致方向与关注重点。
于是上手尝试,看看能不能花半天的时间搞定。全程都参考了这篇文章
IDE环境的准备
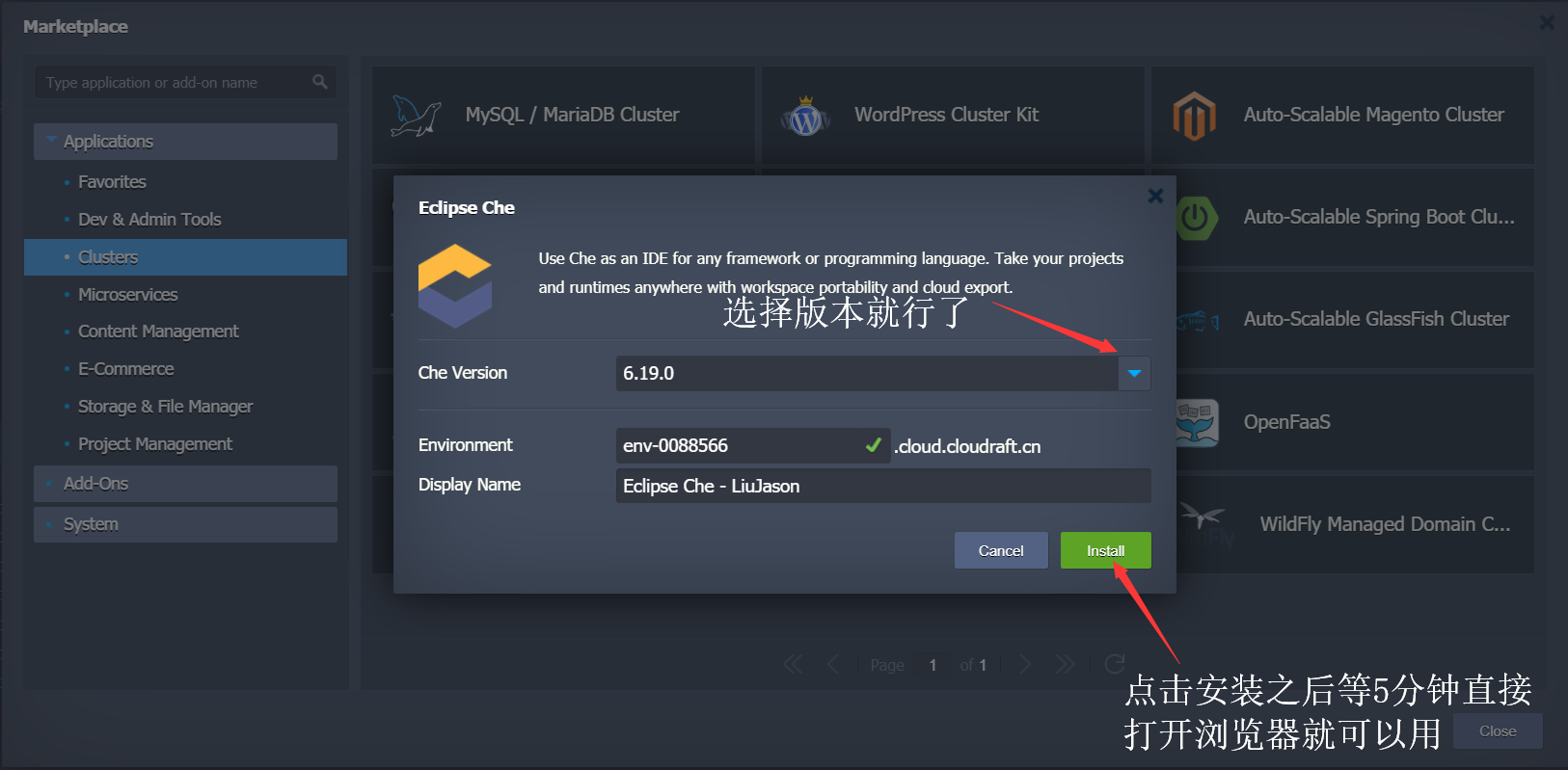
Python在线IDE使用的是EclipseChe,由云筏科技的PaaS云平台一键搭建,全程无需人工配置,而且还能按小时计费:云筏PaaS平台,对于Linux不熟悉的同学来说非常方便呢。我虽然熟悉,但是能省下1个小时部署时间何乐不为呢?
 Python包用到的是:PyPDF2、textract、regex、pandas、numpy、gensim.summarization、rake_nltk
Python包用到的是:PyPDF2、textract、regex、pandas、numpy、gensim.summarization、rake_nltk
实操过程记录
总体思路
1. 导入需要的Python包
2. 把所有PDF文件转换成text
3. 用.findall()函数将关键词提取出来
4. 保存提取出来的关键词清单
5. 用TF-IDF算法来计算每个关键词的权重
6. 保存结果到dataframe然后用.sort_values()来对关键词排序
Python环境选择与配置
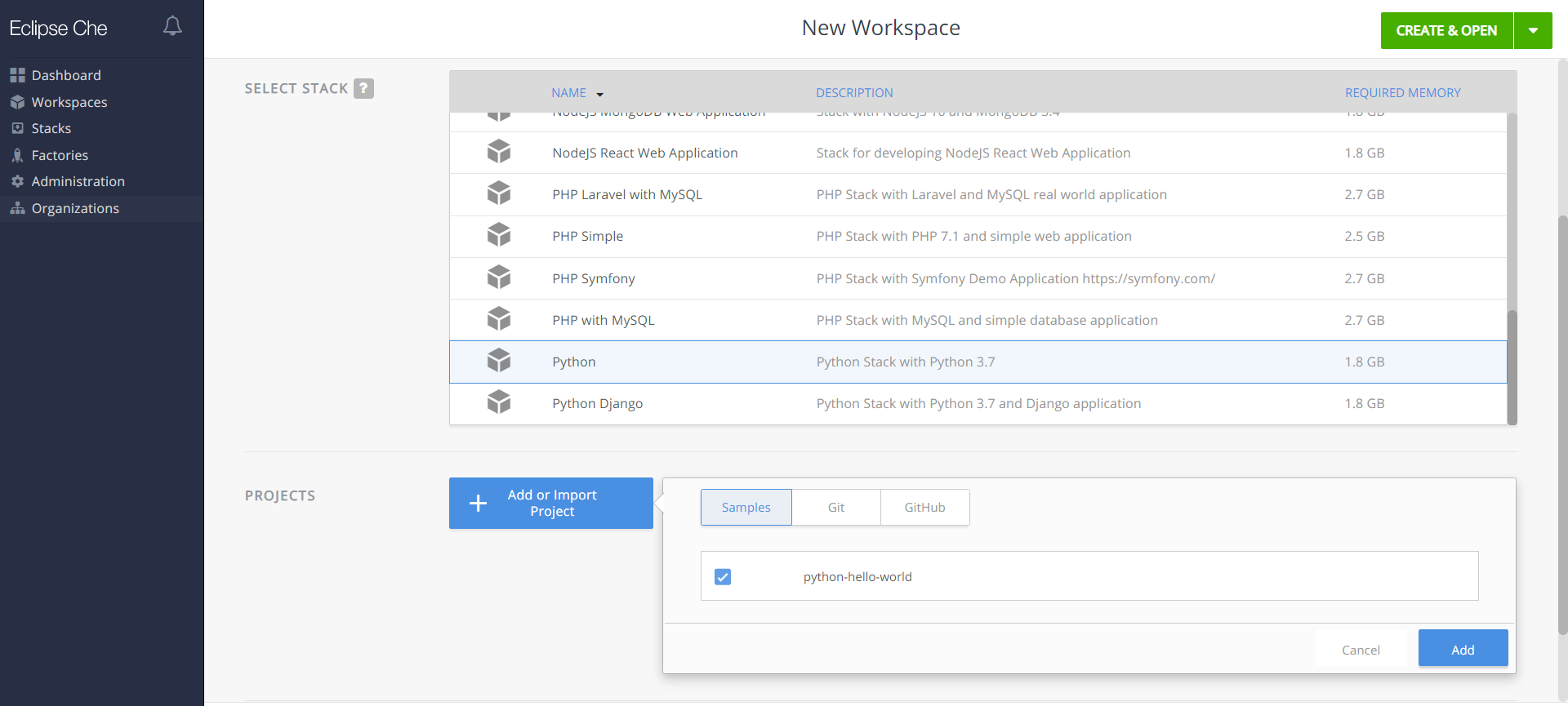
首先进入IDE,选择Python环境,然后部署一个示例项目
 然后载入上面提到的Python包,如果没有的话就用pip安装:
然后载入上面提到的Python包,如果没有的话就用pip安装:
import pandas as pd import numpy as np import PyPDF2 import textract import re
挖个坑,后面再来填吧,有需求看这里
