
在多层次方差分析之后,我们可能需要看看到底是哪些处理组之间有显著差异,或者虽然ANOVA结果是显著的但是我们还要看看哪些处理组之间是不显著的,这种时候我们就需要TukeyHSD事后检验了。用过SPSS的人应该知道,SPSS的事后检验结果非常的人类友好——可读性很高,会把每个层次的处理告诉你,但是R自带的结果就非常不友好了...我拿同一组数据在R和SPSS里跑了TukeyHSD之后截图如下,可以比较一下:
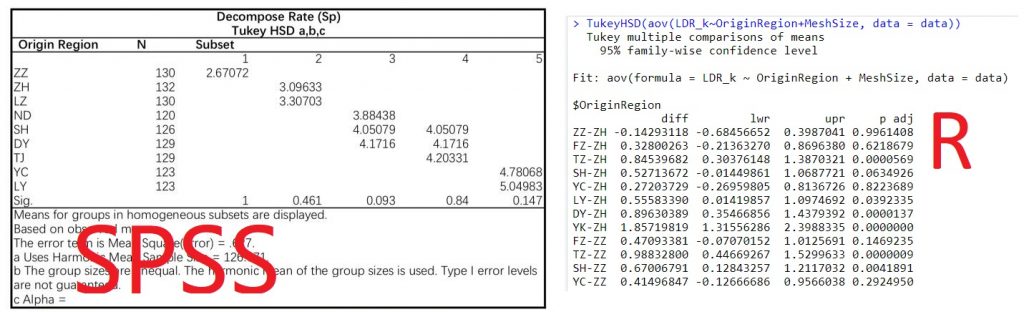
这里就要隆重介绍一下这个agricolae::HSD.test功能了,这里我用和上面一样的数据来跑,先上示例:
library(agricolae)
data <- read.csv("./data/processed/data_std.csv", header = T)[,-1]
fit <- aov(LDR_k~OriginRegion*MeshSize, data = data)
result_O <- HSD.test(fit, "OriginRegion", group = T)
print(result_O)
这给出了如下所示的结果,可以看到在group里已经帮你区分好了,这时候只需要先根据mean的排序拍一下,然后再根据group进行分割即可:
$statistics
MSerror Df Mean CV MSD
0.6822906 378 2.545493e-16 3.244986e+17 0.5432876
$parameters
test name.t ntr StudentizedRange alpha
Tukey OriginRegion 9 4.412161 0.05
$means
LDR_k std r Min Max Q25 Q50 Q75
DY 0.32530631 0.7097809 45 -1.936677 1.4508557 0.02978097 0.384582220 0.77605853
FZ -0.24299496 0.7220485 45 -2.504637 2.3600722 -0.52128563 -0.183408972 0.03558391
LY -0.01516368 0.6193046 45 -2.046281 1.1402315 -0.30250106 -0.044365822 0.38458222
SH -0.04386086 0.7659339 45 -2.064687 1.2636034 -0.36394625 0.034614607 0.44577633
TZ 0.27439923 1.3860926 45 -2.482270 4.8389794 -0.70929808 -0.002696268 0.92462849
YC -0.29896030 0.8934172 45 -2.925010 1.1472782 -0.60000934 -0.215288465 0.35359177
YK 1.28620061 1.0038827 45 -2.137451 4.2718123 0.78673937 1.286135783 1.99981816
ZH -0.57099758 0.5764722 45 -2.609497 0.4941562 -0.73341744 -0.462901382 -0.26275734
ZZ -0.71392877 0.4909817 45 -2.591578 0.9615346 -0.95005760 -0.626076758 -0.50339911
$comparison
NULL
$groups
LDR_k groups
YK 1.28620061 a
DY 0.32530631 b
TZ 0.27439923 bc
LY -0.01516368 bcd
SH -0.04386086 bcde
FZ -0.24299496 cdef
YC -0.29896030 def
ZH -0.57099758 ef
ZZ -0.71392877 f
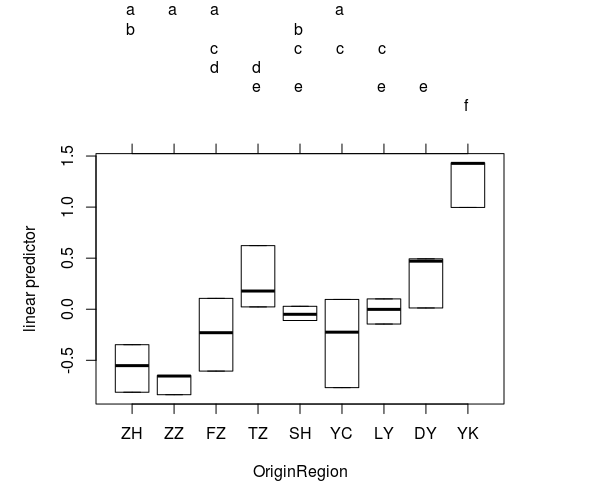
另外还有一个multcomp包提供了可视化的图表绘制功能(参考这里有详细介绍)显著两两比较的,虽然它不以表格的形式呈现出来。但是,它有一个绘图方法,可以使用箱线图方便地显示结果。演示顺序也可以更改(选项decreasing=),并且它有更多的选项可用于多重比较。还有multcompView包扩展了这些功能。
以下是使用以下分析的相同示例:
library(multcomp) tukey <- glht(fit, linfct = mcp(OriginRegion = "Tukey")) summary(tukey) tukey.cld <- cld(tukey) opar <- par(mai=c(1,1,1.6,1)) plot(tukey.cld) par(opar)
在所选级别(默认为5%),共享相同字母的处理之间没有显着差异。
顺便提一下,有一个新项目,目前托管在R-Forge上,看起来很有希望:factorplot。它包括基于行和字母的显示,以及所有成对比较的矩阵概览(通过水平图)。可在此处找到工作文件:factorplot:改进GLM中简单对比度的表示
